
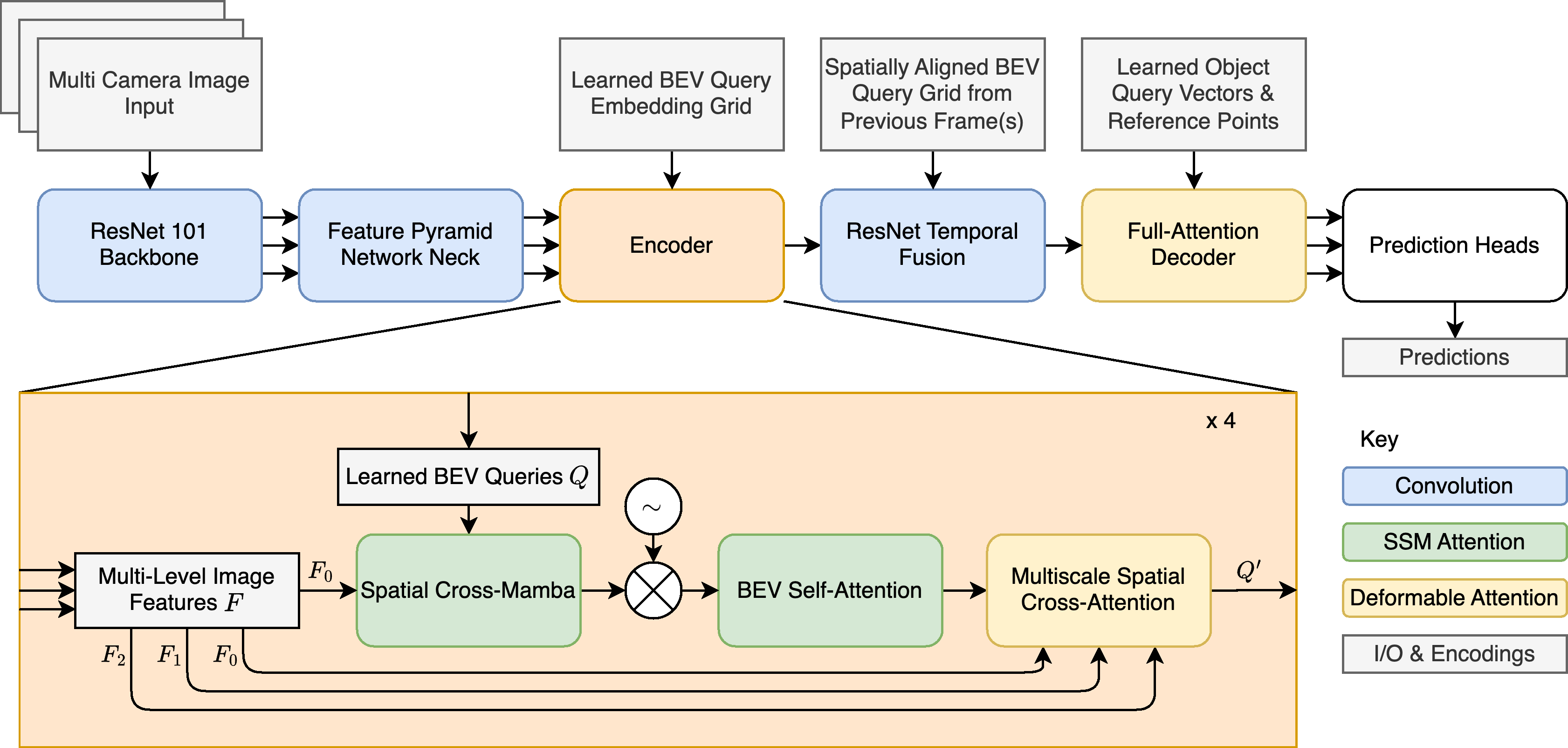
Automatically generating a bird’s-eye-view (BEV) of an object’s surrounding environment is critical for applications like autonomous driving and advanced driver-assistance systems. These systems rely on integrating signals from multiple cameras to construct a top-down view of the environment. Prominent examples include the BEV systems deployed in Tesla cars. However, many existing methods heavily depend on Transformers, which employ computationally expensive attention mechanisms to learn accurate representations.
In this work, we introduce Spatial Cross Mamba, an innovative approach analogous to standard cross-attention in Transformers. Our method leverages the efficiency of state space models (SSMs) to significantly reduce the computational overhead associated with Transformers, enabling more efficient and scalable BEV systems without compromising representation accuracy.
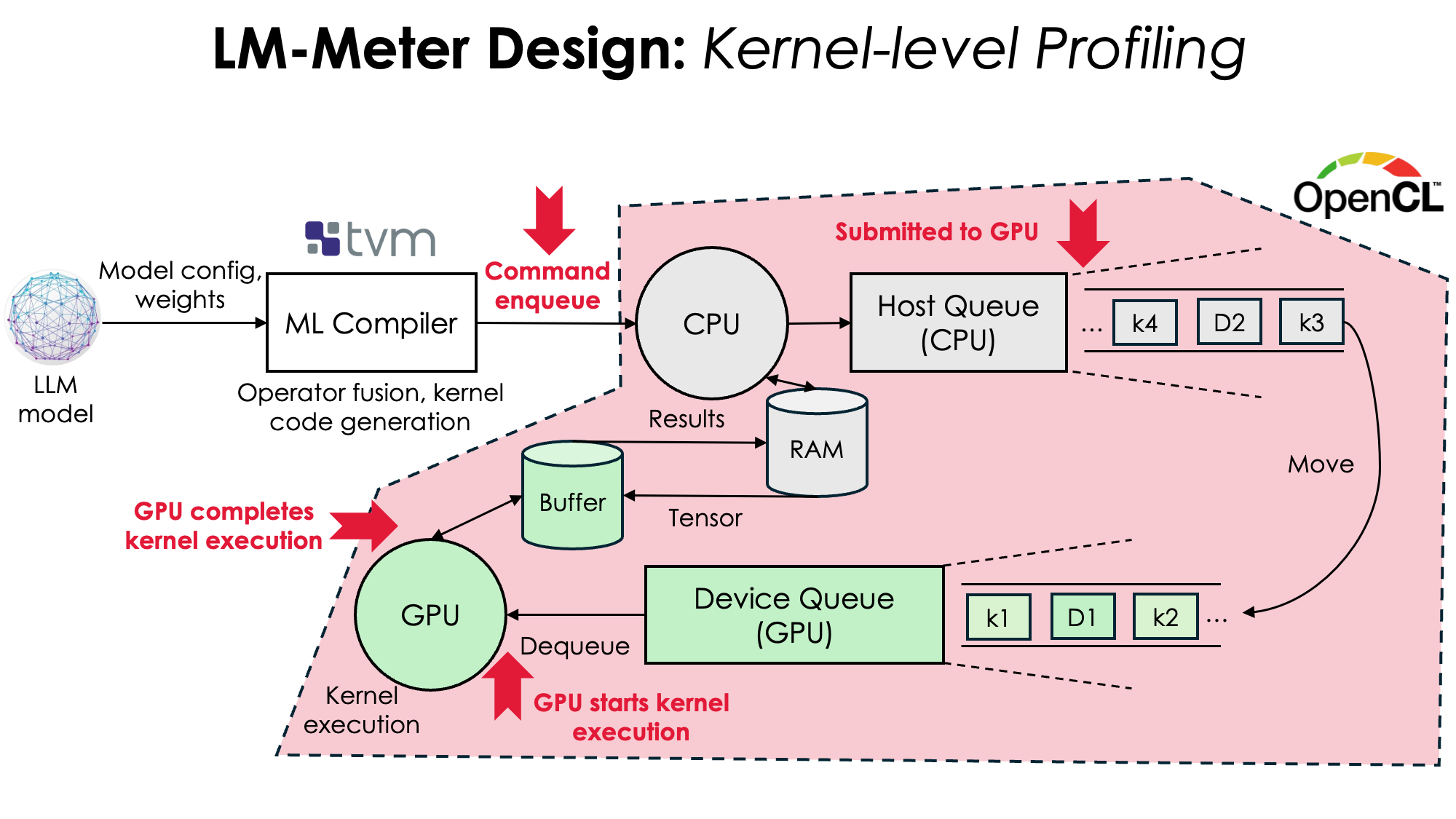
Running LLMs locally on mobile and edge devices promises improved privacy, reliability, and lower communication costs, but remains challenging due to high resource demands and limited visibility into performance-efficiency trade-offs. We present lm-Meter, the first lightweight, online latency profiler for on-device LLM inference. lm-Meter provides fine-grained, real-time phase- and kernel-level latency profiling without auxiliary devices. Implemented on commercial mobile platforms, lm-Meter achieves high accuracy with minimal overhead (2.58% prefill and 0.99% decode throughput loss under the most constrained power settings). Leveraging lm-Meter, we conduct comprehensive empirical studies revealing phase- and kernel-level bottlenecks in on-device LLM inference, quantifying accuracy-efficiency trade-offs, and identifying systematic optimization opportunities. lm-Meter provides unprecedented visibility into the runtime behavior of LLMs on constrained platforms, laying the foundation for informed optimization and accelerating the democratization of on-device LLM systems.
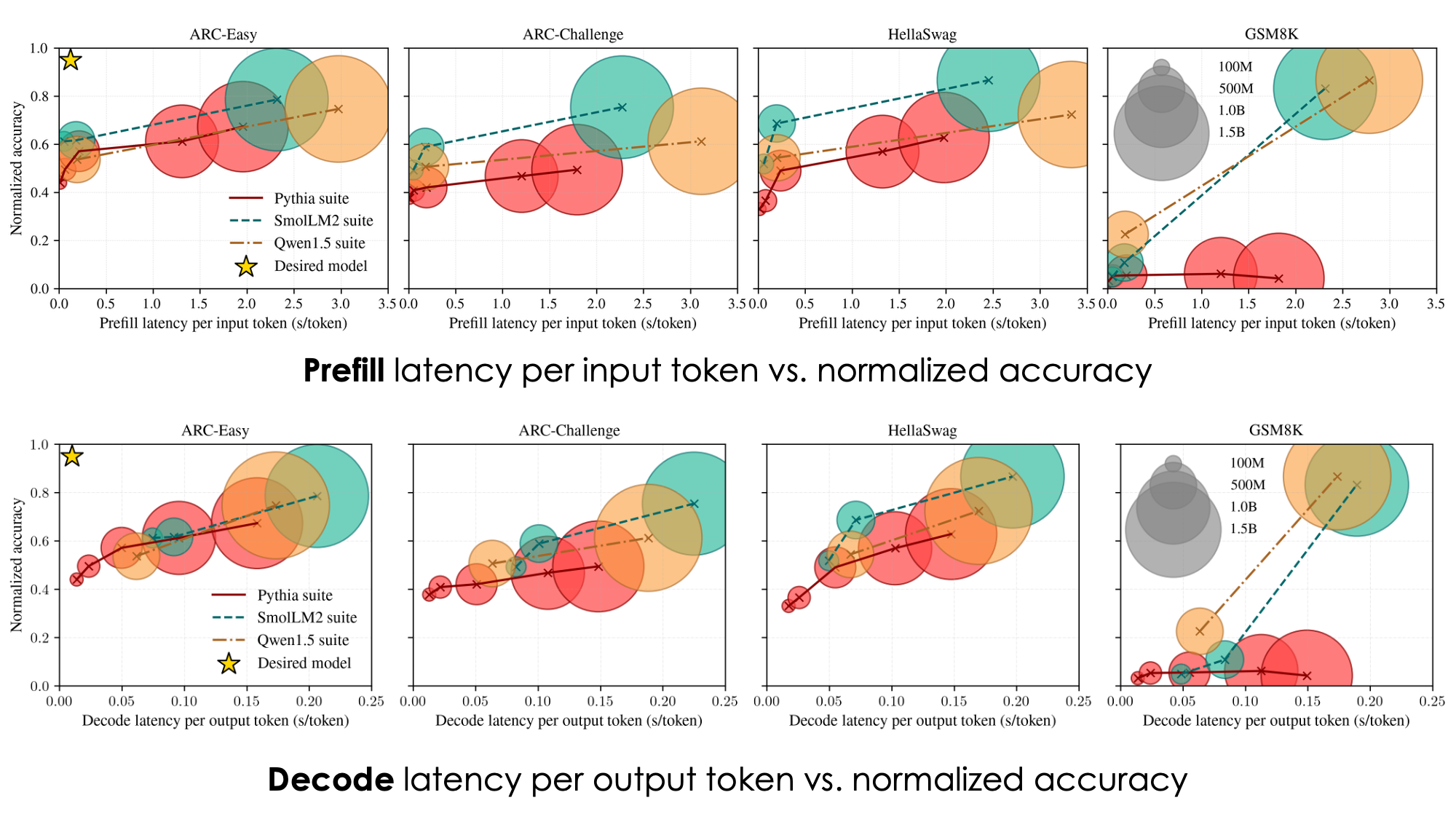
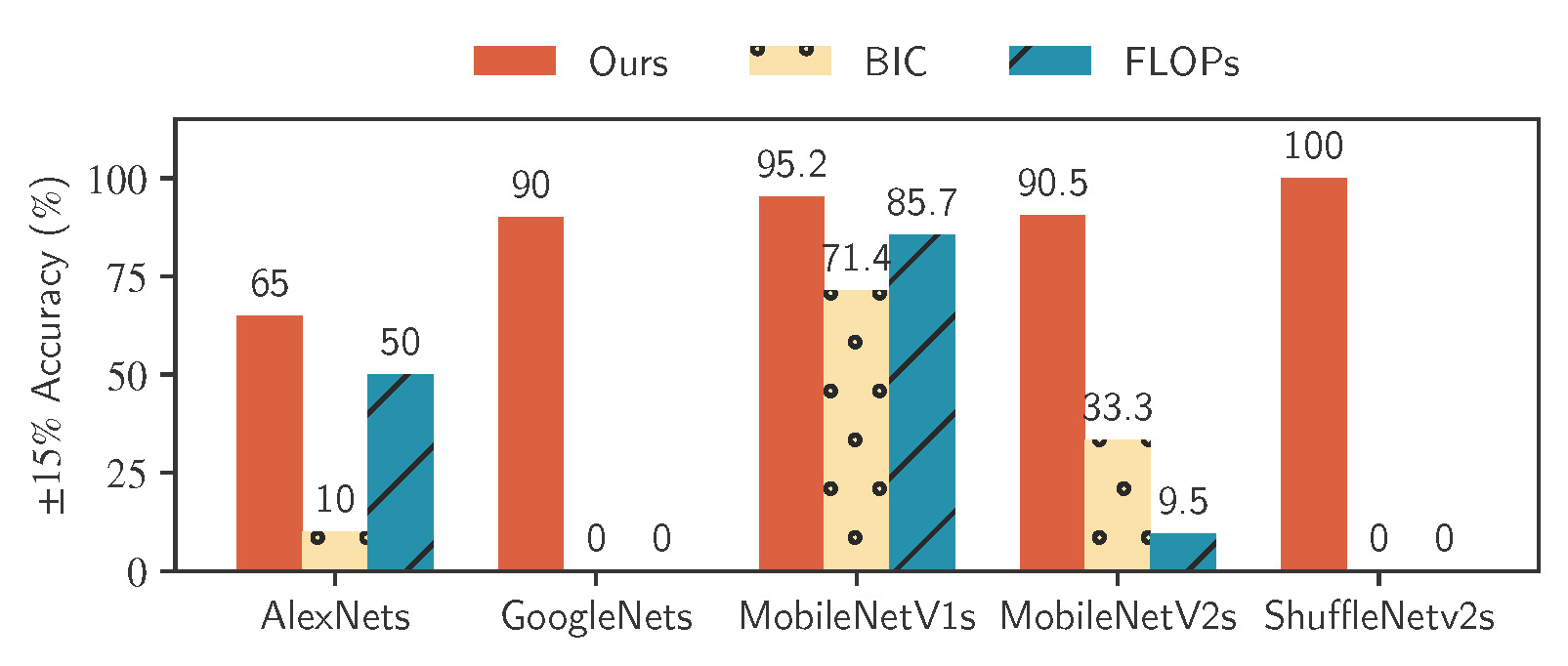
PlatformX is an end-to-end, fully automated platform for hardware-aware Neural Architecture Search (HW-NAS) targeting energy-efficient deep neural networks on mobile and edge devices. PlatformX integrates four key components: (i) an energy-driven search space that expands conventional NAS design by incorporating energy-critical configurations, enabling exploration of high-efficiency architectures; (ii) a transferable kernel-level energy predictor across devices and incrementally refined with minimal on-device samples; (iii) a Pareto based multi-objective search algorithm that balances energy and accuracy to identify optimal trade-offs; and (iv) a high-resolution runtime energy profiling system that automates on-device power measurement usingexternal monitors without human intervention.
Despite the remarkable advances in edge device capabilities such as functionality, computation power, and storage capacity, the limited energy capacity has been the major bottleneck in promoting advanced edge AI applications. For instance, mobile and edge devices are typically powered solely by embedded batteries, so their energy capacity is significantly constrained by form factor requirements, safety considerations, manufacturing costs, and concerns on the environmental impact of the battery technology used.
In this work, we studied the problem of accurate energy measurement, prediction, and understandable scoring of on-device deep learning across edge hardware. We created kernel-, model-, and application-level datasets for on-device deep learning. We designed and implemented the first kernel-level energy predictors on both mobile CPU and GPU. It can provide consistently accurate energy estimation on unseen DNN models.
The goal of this research pillar is to improve system performance, especially latency and energy efficiency, of mobile AR/VR devices. We primarily focus on adapting the system configurations of mobile AR devices to address the trade-offs between user preferences and performance requirements.
We are also recently interested in prototyping systems for emerging AR applications including: collaborative AR, mobile AR with generative AI, AR for scientific data exploration, etc.
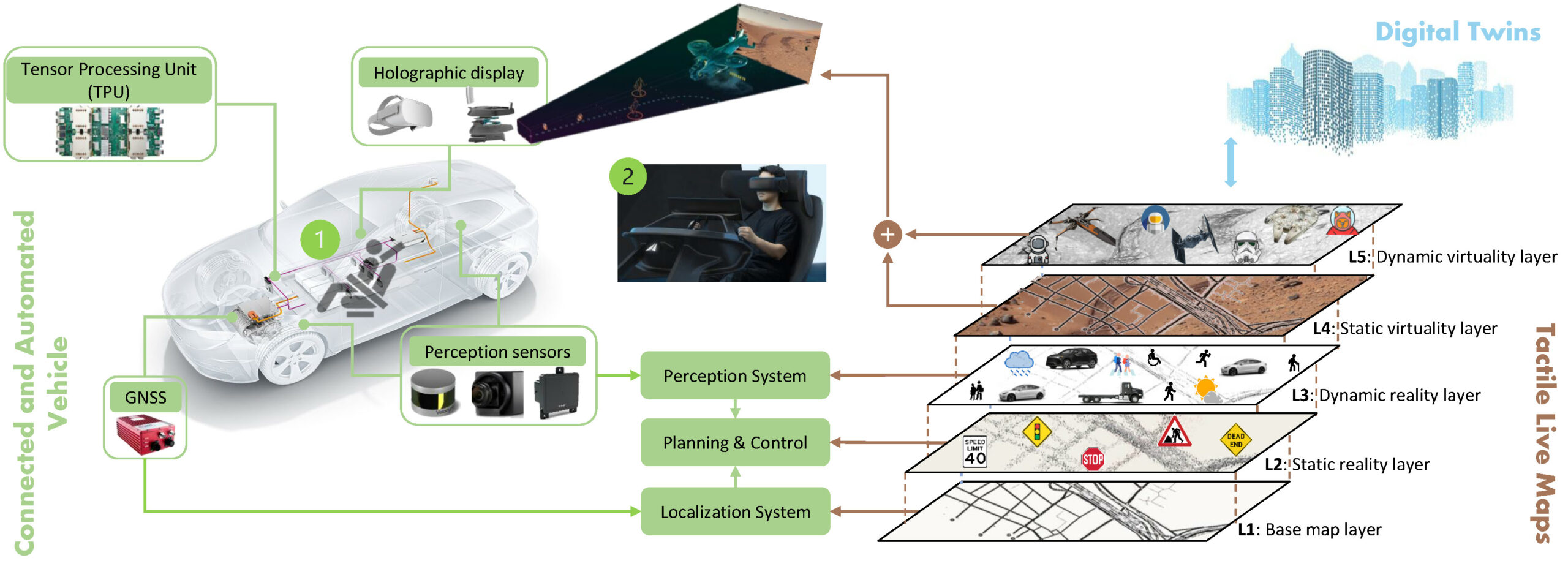
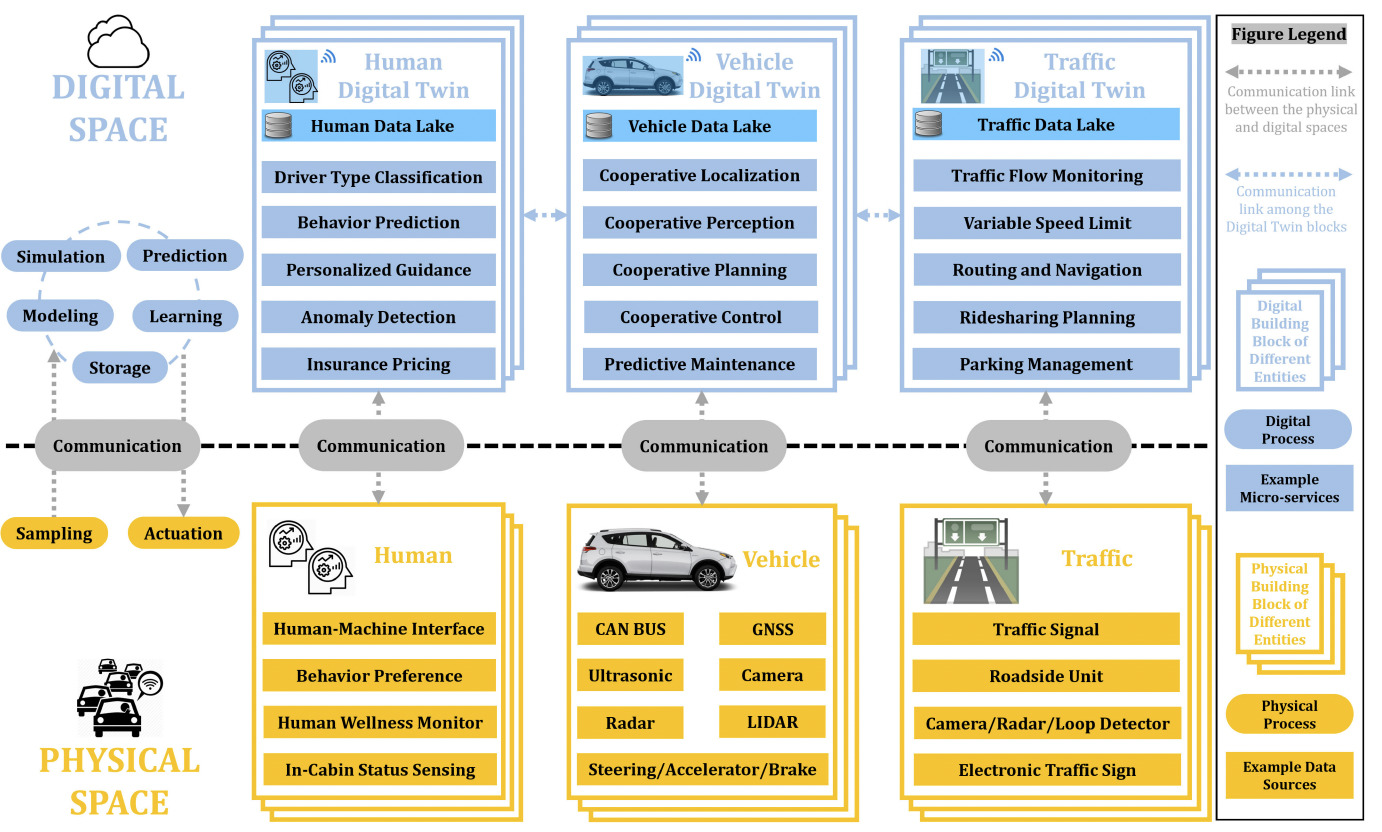
The goal of this research pillar is to conduct pioneering study on digital twins for connected and automated vehicles (CAVs). Our vision is to create fair, affordable, and efficient mobility solutions by leveraging digital twins and edge computing.
We are primarily interested in: Visualization of mobility digital twin with NeRF, cooperative perception, security in CAVs, etc.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}